넷플릭스의 네 가지 알고리즘
넷플릭스는 2015년 미국 컴퓨터 학회(Association for Computing Machinery, ACM)에서 9개의 추천 알고리즘을 발표했습니다.* 그중 핵심이 되는 알고리즘 4개를 추려 소개해 드립니다.
* 관련 논문: The Netflix Recommender System: Algorithms, Business Value, and Innovation (2015.12)
1. 개인별 인기 추천(PVR, Personal Video Ranker)
개인별 인기 추천(Personal Video Ranker, 이하 PVR)은 가장 기본적인 추천 기법으로, 콘텐츠에 대한 이용자의 예상 별점을 계산해 높은 순서대로 보여주는 알고리즘입니다. 아직 시청하지 않았지만, 시청한다면 얼마나 만족할 것인지 계산해 예측하는 것이죠. 이렇게 계산된 예상 선호도를 근거로 콘텐츠의 순서를 개인화할 수 있습니다.

좀 더 세분화해서 살펴보자면, PVR은 총 세 단계를 거칩니다.
1단계: 나와 성향이 유사한 다른 이용자, 즉 나와 비슷하게 별점을 주는 다른 이용자를 찾는다.
2단계: 그 이용자 중 특정 콘텐츠를 본 이용자의 별점 평가를 분석한다.
3단계: 내가 이 콘텐츠를 시청한다면 몇 점을 줄 것인지 예상한다.
추천의 정확도를 높이기 위해 장르, 감독, 출연 배우 데이터 등을 기준으로 이용자가 그동안 시청했던 콘텐츠와 비교 분석하기도 합니다. 또한 유사한 콘텐츠들의 시청 중단 여부 또한 예상 별점에 반영됩니다.
2. 인기 콘텐츠 추천(Top-N Video Ranker)
인기 콘텐츠 추천(Top-N Video Ranker, 이하 Top-N)은 특정 기간 동안 많이 시청된 순서로 콘텐츠를 추천하는 알고리즘입니다. 즉, 기간과 시청 건수를 같이 고려함으로써 랭킹 순서를 도출하는 방식입니다.
기간을 3일, 7일 등으로 길게 설정하면 스테디셀러가 추천됩니다. 1시간, 3시간 등으로 짧게 설정하면 시간대별로 딱 그 시간에 유입되는 이용자의 관심사에 따라 순서가 정해지기 때문에 트렌디한 콘텐츠를 추천할 수 있습니다. 집계 기간을 조절하는 것만으로 스테디셀러 추천과 트렌드 콘텐츠 추천을 오갈 수 있습니다.

시청 건수 대신 다른 액션데이터*인 '좋아요' 수, 검색 건수를 사용해 콘텐츠를 추천할 수도 있습니다. 또한 시청, '좋아요', 검색 건수를 특정 비율로 조합해 추천하는 방법도 가능합니다. Top-N 알고리즘을 다양하게 디자인할 수 있다는 말입니다.
* 챕터 2 참고
Top-N 알고리즘은 유·무료 콘텐츠를 모두 제공하는 IPTV 같은 플랫폼에서도 사용됩니다. 여기서 만약 시청 건수로만 Top-N 알고리즘을 짜면 무료 콘텐츠 중심으로 추천되는 현상이 발생합니다. 수익을 내는 데에는 딱히 도움이 되지 않겠죠. 따라서 유료 콘텐츠도 같이 추천하기 위해 구매 건수를 기준으로 알고리즘을 구성하기도 합니다.
인터넷 포털에 있는 '댓글 많은', '많이 본', '공감 많은' 뉴스 큐레이션 역시 Top-N 알고리즘을 사용한 것입니다. 네이버 포털의 '공감 많은 뉴스'는 6시간 주기로 기사의 '공감' 수 합계를 갱신함으로써 하루에 네 차례 업데이트된다고 합니다.
* 출처: 네이버 뉴스 서비스 안내
넷플릭스의 Top-N 알고리즘은 기간, 시청 건수와 함께 메타데이터를 활용하기도 합니다. 다음은 제작 국가, 주인공 성별이라는 메타데이터가 활용된 경우입니다. 주인공을 여성으로, 제작 국가를 한국이 아닌 곳으로, 장르를 TV 프로그램(영화나 다큐가 아닌 것)으로 알고리즘을 짜면 콘텐츠가 아래와 같이 구성될 수 있습니다.

반면 키워드를 '아포칼립스'로, 제작 국가를 '미국이 아닌 곳'으로, 장르를 TV 프로그램으로 모델링하면 아래와 같이 추천될 수 있습니다. 메타데이터를 응용하면 수많은 '경우의 수'를 활용해 다양한 추천이 가능합니다.

Top-N 알고리즘을 적용할 때는 한 가지 현상을 조심해야 합니다. 바로 피드백루프(feedback loop) 현상입니다.
우리에게는 좋아하는 콘텐츠를 시청하는 성향도 있지만, 먼저 눈에 띄는 콘텐츠를 시청하는 경향도 있습니다. 피드백루프는 먼저 눈에 띄는 것을 시청하는 경향이 추천 알고리즘에 영향을 줌으로써 생기는 문제입니다.

눈에 띄는 콘텐츠를 시청하는 경향에 따라, 이용자들은 딱히 선호하는 콘텐츠가 아니더라도 잘 보이는 곳에 위치한 콘텐츠를 클릭합니다. 그리고 일단 클릭하면 해당 콘텐츠는 Top-N 알고리즘에 의해 다시 추천될 확률이 높아집니다. 시청 건수에 +1이 되기 때문입니다. 단지 좋은 자리에 노출됐기 때문에 +1이 되는 것입니다.
따라서 한번 Top-N 알고리즘에 의해 노출되면, 해당 콘텐츠는 계속 클릭을 유도하고 그에 따라 시청 건수가 올라가면서 추천 랭킹에 지속적으로 머무르게 됩니다. 이런 방식으로 피드백루프는 추천 랭킹 결과를 왜곡시킵니다.
하지만 피드백루프 현상을 완화하는 방법이 있습니다. 첫째, 콘텐츠가 노출된 위치에 따라 집계되는 시청 건수에 가중치를 부여하는 것입니다. 잘 보이는 위치에 노출된 콘텐츠를 시청하는 것보다 잘 안 보이는 위치에 노출된 콘텐츠를 시청했을 때 해당 콘텐츠에 높은 점수를 부여하는 식입니다.*
* 관련 논문: Recommending what video to watch next: a multitask ranking system. 여기서 구글 유튜브 팀은 피드백루프 현상에 대한 해결 방법을 발표했다.
두 번째는 시청의 몰입 정도를 판단하여 랭킹 알고리즘을 검증하는 방법입니다. 구체적으로 말하자면 동영상의 시청 중단 위치를 분석하는 것인데요. 가령 10%까지만 시청하고 중지·이탈한 이용자의 행위를, 실수로 클릭했거나 혹은 '관심은 없는데 그냥 눈에 띄어서 클릭한 것'으로 해석하는 것입니다. 이렇게 해석된 콘텐츠는 랭킹에 반영되지 않습니다.
반대로 시청 중단 위치가 10%를 넘겼다면, 이 행위는 선호하는 콘텐츠를 시청한 것으로 여겨지고 랭킹에 반영됩니다. 여기서 10%라는 수치는 예로 든 것일 뿐, 실제로는 플랫폼과 도메인마다 다르게 설정됩니다.
3. 지금 화제가 되는 콘텐츠 추천(Trending Now)
지금 화제가 되는 콘텐츠 추천(Trending Now, 이하 트렌딩나우)은 특정 시기에 나타나는 이용자의 콘텐츠 소비 패턴을 분석하여, 그에 맞는 콘텐츠를 추천하는 알고리즘입니다. 넷플릭스가 언급한 예시는 이용자들이 발렌타인데이 전후로 로맨틱 영화를 찾고, 인구 밀집 지역에 허리케인이 온다고 보도되면 해당 지역 이용자들이 자연 다큐멘터리를 찾는다는 것입니다. 트렌딩나우는 이러한 경향을 반영하는 알고리즘입니다.
이용자의 관심사가 특정한 경향을 띠지 않을 때는 Top-N 알고리즘과 유사하게 작동하게 됩니다. 아래 그림의 '지금 뜨는 콘텐츠'처럼 해당 시기에 개봉했거나 유행하고 있는 콘텐츠가 추천되는데, 이는 시청 내역을 지역별로 구분하고 시간대별로 매우 촘촘하게 계산하는 Top-N 알고리즘의 응용으로 볼 수 있습니다.

트렌딩나우 알고리즘은 특정 지역을 근거로 콘텐츠를 추천하기도 합니다. 부산 이용자에게는 영화 <부산행>, <해운대>와 같은 부산 관련 콘텐츠를 우선적으로 추천하는 것입니다. 부산 관객에게 부산은 상시적 화젯거리일 수밖에 없으니까요. 실제로 천만 관객을 동원한 두 영화의 부산 지역 관객 점유율은 각각 8.4%, 11.3%로 다른 천만 영화였던 <신과 함께: 인과 연>(7.5%)에 비해 더 높았습니다.*
* 출처: 영화진흥위원회
극장 개봉작이 하나의 트렌드가 되기도 합니다. 극장에서 개봉되는 것만으로 화제가 되는 블록버스터들이 있습니다. <겨울왕국 2>, <어벤져스> 등이 그런 경우입니다. 동영상 콘텐츠 플랫폼에서는 두 시리즈의 이전 작품들이 트렌딩나우 알고리즘을 통해 이용자에게 노출될 수 있을 것입니다.
시상식도 유의미한 트렌드입니다. <기생충>이 칸영화제에서 황금종려상을 받았을 때, 또 아카데미 시상식에서 4관왕을 했을 때 각종 영상 플랫폼에서는 봉준호 감독의 작품들이 인기 콘텐츠로 추천되기 시작했습니다.
4. 페이지 제너레이션(PG, Page Generation)
PVR, Top-N, 트렌딩나우 등이 이용자가 선호할 만한 콘텐츠를 추천하는 것이라면 지금 말씀드릴 페이지 제너레이션(Page Generation, 이하 PG)은 여러 콘텐츠를 나란히 묶어 하나의 블록(row)을 만들고, 이렇게 구성된 여러 개의 블록을 화면에 노출하는 알고리즘입니다.

PG는 위의 그림처럼 여러 블록(rows) 중에서 내가 좋아할 10~40개의 블록을 추천해주는 알고리즘입니다. 블록은 각각 PVR, Top-N, 트렌딩나우와 같은 알고리즘으로 만들어지지만, 이렇게 만들어진 블록 중 이용자에게 노출할 블록을 최종적으로 결정하는 알고리즘이 PG입니다. 넷플릭스는 수천 개의 블록을 만드는 알고리즘과 만들어진 블록을 이용자에게 10~40개씩 계속 바꿔가며 추천하는 알고리즘으로 구조화되어 있습니다.
알고리즘은 몇 개에 불과한데 수천 개의 블록이 생성될 수 있다는 것이 의아할 수 있지만, 위에서 언급한 대로 액션데이터와 메타데이터를 조합하면 생성 가능한 블록의 수는 기하급수적으로 늘어납니다.
애니메이션을 예로 들어보죠. '제작 국가'라는 메타데이터를 활용하면 일본 애니메이션과 국내 애니메이션으로 최소 2개의 블록을 생성할 수 있습니다. 제작사 메타데이터를 통해서는 디즈니 애니메이션 블록을 만들 수 있습니다. 캐릭터 메타데이터를 활용하면 여성이 주인공인 애니메이션이나 동물이 등장하는 애니메이션 블록을 만들 수 있습니다. 장르 데이터를 조합하면 드라마 애니메이션이나 액션 애니메이션, SF 애니메이션 블록 형성도 가능합니다.
넷플릭스에 로그인할 때마다 달라지는 블록의 구성과 순서는 이용자 선호도, 최근 트렌드, 콘텐츠 프로모션* 등을 고려해 결정되는데요. 블록을 구조화하는 옵션은 크게 세 가지로 나뉩니다.
* 넷플릭스가 보여주고 싶은 콘텐츠
첫 번째 옵션은 'Fixed(고정)'입니다. Fixed로 설정된 블록은 지정된 위치 내에 항상 노출되고 대부분의 고객에게 추천됩니다. 넷플릭스 오리지널은 대부분의 고객에게 화면의 상단 10번째 이내에서 항상 노출되므로 Fixed에 해당합니다.

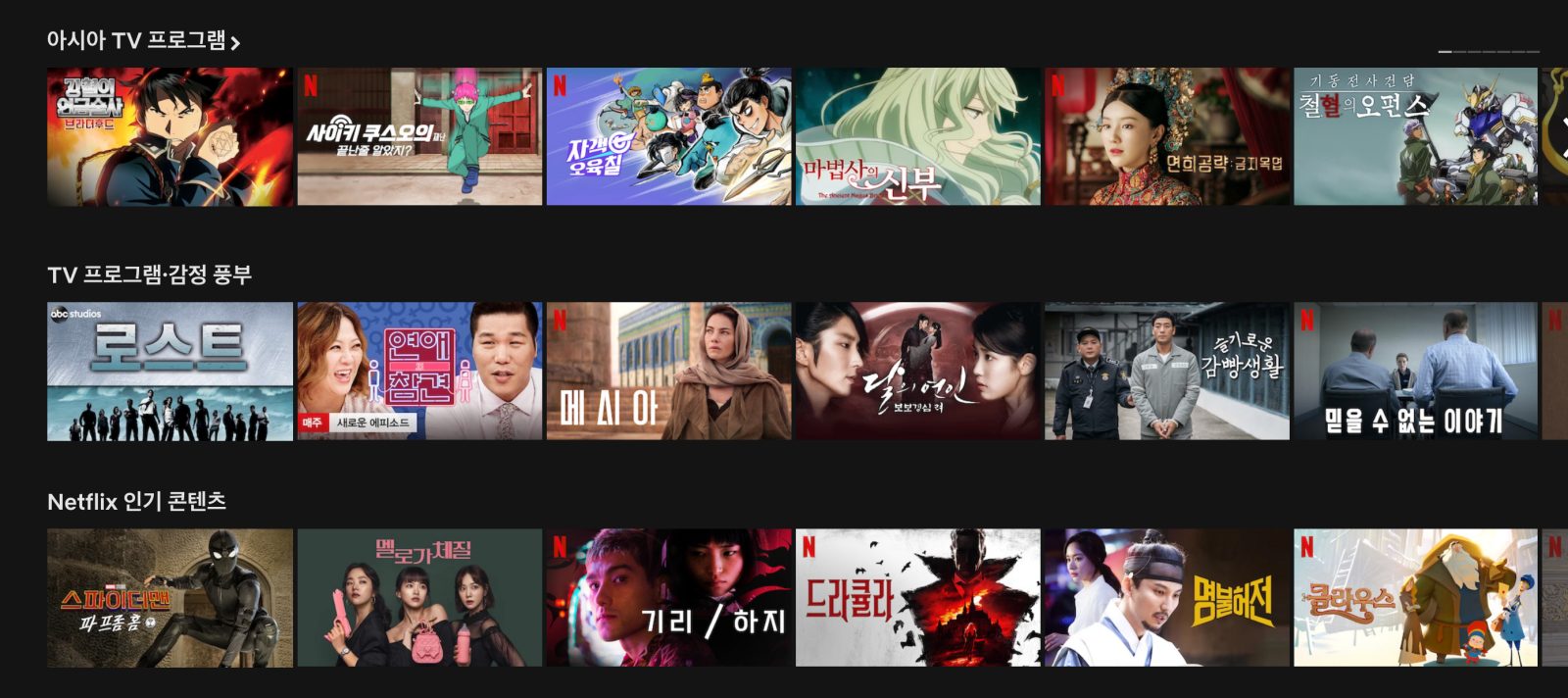
다음은 'Movable but Mandatory(선호 고정)'입니다. 이 블록은 높은 확률로 이용자에게 노출되지만 이용자의 선호도에 따라 노출 위치가 달라집니다. 넷플릭스의 'Netflix 인기 콘텐츠' 블록이 대표적입니다. 아래 이미지를 보면 첫 번째 위치에 노출되던 'Netflix 인기 콘텐츠 블록'이 세 번째 위치로 이동한 것을 확인할 수 있습니다.

마지막으로 'Movable but Optional(선택 고정)'입니다. 이용자의 선호도에 따라 블록을 노출할 수도, 노출하지 않을 수도 있는 옵션입니다. 'Netflix 인기 콘텐츠 블록', '시청 중인 콘텐츠' 블록을 제외한 대부분의 블록이 여기에 해당합니다. 대표적인 예시로는 'Because You watch(OO을 시청한 사람을 위한 추천, 이하 BYW) 같은 추천 기법이 있습니다.
아래 '<좋아하면 울리는>과 비슷한 콘텐츠' 블록의 경우, <좋아하면 울리는>을 시청한 이용자에게만 노출됩니다. 노출되는 위치는 <좋아하면 울리는>에 대한 선호도에 따라 제각각입니다.

영상을 넘어 일반 상품까지, 범용 알고리즘
지금부터 소개드릴 두 개의 알고리즘은 콘텐츠뿐 아니라 다른 여러 플랫폼에서도 자주 사용되는 알고리즘입니다. 다양한 분야에서 알고리즘을 활용하려면 꼭 알아둬야 할 내용이라 따로 정리했습니다.
1. 공동 기반 필터링(CF, Collaborative Filtering)
협업필터링(Collaborative Filtering, 이하 CF)은 이용자가 좋아할 만한 것을 예측하여 추천한다는 점에서 넷플릭스의 PVR 알고리즘과 비슷합니다.
온라인 쇼핑을 하다가 '다른 고객이 함께 본 상품'이나 '이 책을 구매한 분들이 구매한 다른 책'과 같은 표현을 보신 적 있나요? 여기에 사용된 추천 알고리즘이 바로 CF입니다.
A, B, C, D 4개의 콘텐츠가 있다고 가정하고 A와 B 콘텐츠를 모두 시청한 이용자는 5명, A와 C 콘텐츠를 모두 시청한 이용자는 10명, 이런 식으로 아래와 같은 표를 만들어 봅시다.

이런 조건에서 CF 알고리즘을 사용하면 우리는 A 콘텐츠를 시청한 이용자에게 다음에 어떤 콘텐츠를 추천해야 하는지 파악할 수 있습니다. CF 알고리즘은 A를 시청한 이용자가 많이 본 영상, 즉 D-C-B의 순서로 콘텐츠를 추천할 것입니다. 콘텐츠 A와 D를 모두 시청한 경우가 15건으로 가장 많고 A와 B를 모두 시청한 경우는 5건으로 가장 적기 때문입니다.
그런데 시청했지만 재미가 없어서 이내 중단한 경우, CF 알고리즘에 영향을 줍니다. CF 알고리즘을 통해서도 피드백루프 현상이 발생할 수 있다는 것입니다. 앞부분만 보고 꺼버린 영상이 시청 건수가 발생했다는 이유로 추천되고, 추천을 받은 다른 이용자는 다시 시청하고, 시청이 된 콘텐츠는 랭킹에 계속 머무르는 순환 구조가 생길 수 있습니다. 이런 구조는 궁극적으로 추천 정확도를 떨어뜨릴 것입니다.
이러한 문제는 알고리즘에 시청 건수 대신 별점이나 '좋아요' 같은 명시적 데이터를 입력하는 것으로 완화할 수 있습니다. 아래 표는 매트릭스를 시청 건수에 '좋아요' 데이터를 더한 것입니다(괄호 안에 있는 숫자가 '좋아요 수'입니다).

'좋아요' 수를 기준으로 CF 알고리즘을 돌렸다면, A를 시청한 고객에게는 C-D-B 순서로 콘텐츠를 추천하는 것이 합리적입니다. A와 C에 모두 '좋아요'를 누른 경우가 8건으로 가장 많기 때문입니다. 이상에서 알 수 있듯, 알고리즘에 어떤 데이터를 대입하는지에 따라 알고리즘의 활용 범위와 추천 결과가 달라집니다. 데이터는 알고리즘만큼이나 콘텐츠 추천 정확도에 큰 영향을 미칩니다.
2. 콘텐츠 기반 필터링(CBF, Content Based Filtering)
콘텐츠 기반 필터링(Content Based Filtering, 이하 CBF)은 비슷한 콘텐츠를 추천하는 기법입니다. CF 알고리즘과 다른 점은 활용하는 데이터입니다. CF가 시청, 구매, '좋아요' 같은 액션데이터를 활용해 콘텐츠를 추천하는 알고리즘인 반면, CBF는 콘텐츠의 메타데이터만을 활용해 비슷한 콘텐츠를 추천합니다.
영화 같은 미디어 콘텐츠는 제목, 장르, 출시일, 출연 배우 등의 메타데이터를 활용해 유사도가 높은 콘텐츠를 연관 콘텐츠로 추천합니다. 출연 배우가 겹치거나 장르가 동일할 때 또는 출시일이 비슷한 경우에 관련성이 높은 콘텐츠로 분류되는데, 특정 배우가 나오는 작품을 골라 보거나 선호하는 장르가 뚜렷한 이용자에게 적합한 추천 기법입니다. 음원 스트리밍 사이트에서 제공되는 '비슷한 장르의 아티스트 추천' 서비스 역시 CBF 알고리즘을 사용한 사례입니다.
지금까지 넷플릭스의 사례를 통해 대표적인 추천 알고리즘 네 가지와 일반적인 추천 알고리즘 두 가지를 살펴보았습니다. 수백 가지의 알고리즘이 매년 업데이트되지만 원리는 크게 다르지 않기에, 위의 알고리즘을 알아두는 것이 의미가 있습니다.
이어지는 챕터에서는 유튜브의 추천 알고리즘을 자세히 들여다보고, 유튜브에서 콘텐츠를 효과적으로 유통시키기 위해서는 어떤 지표를 눈여겨보아야 할지 말씀드리겠습니다.
 2분 분량
2분 분량